Inserting Data with Dependencies
- Concurrency Problems
- PHP Code
- Error control and transactions
- Task – Play around with transactions
- Summary
You have seen that relational database requires to divide information into columns and rows – this gives us tables with records as a result. A record in such a table has a given structure. Sometimes there is a need to store related information into multiple tables – there can be many reasons for that:
- Records are naturally separable by common reasoning or by application design needs (e.g. product images are stored in another table than the products themselves).
- Record in one table can be shared by records in other tables (e.g. an address can be shared among many persons whom happen to live in the same building or an address can be shared by a person and also can be used as a meeting location).
- Other technical reasons – mostly defined by database normalization rules which should be obeyed during the database structure design process.
Records are then connected by foreign keys which contain information about relationships between tables.
Let’s think about a simple scenario based on your database structure – you want to create a form, where the users of your application could fill (in a single step) the information about a person and information about the address of this person. This is quite helpful because users do not need to create the address record beforehand.
In your database schema, you have the table person and the table location. After the examination of columns in these two
tables you find out that the table person has the column id_address which also has a defined
foreign key pointing into the table location.
This means that in the person table you can define a link for each record to the location table using the value from
the column id_location of the table location. This also means that multiple persons can share one address (imagine that
they live in one household as a family).
Because te person links to the address, you have to insert information about the address first. Then somehow find the ID assigned to that new row (remember that it is auto-generated), store the ID in local variable of the script. Then you can insert the the row with person information which will include the ID of the new address. The only problem is how to find the auto-generated ID.
Concurrency Problems
If you work with the database alone (when you develop an application), the state of the database does not change unless
you do something. In a real world situation, there can be many other users changing the database through your application
at any moment. This basically means that you cannot INSERT the data and then SELECT e.g. the highest ID from the table.
The problem is that many other users’ INSERT commands could be executed between your INSERT and your SELECT MAX()... command. You have to ask the database system specifically for ID of
last insertion in in your session. Session is
basically a connection between your application and the SQL server. Session is initiated during the startup of
your application.
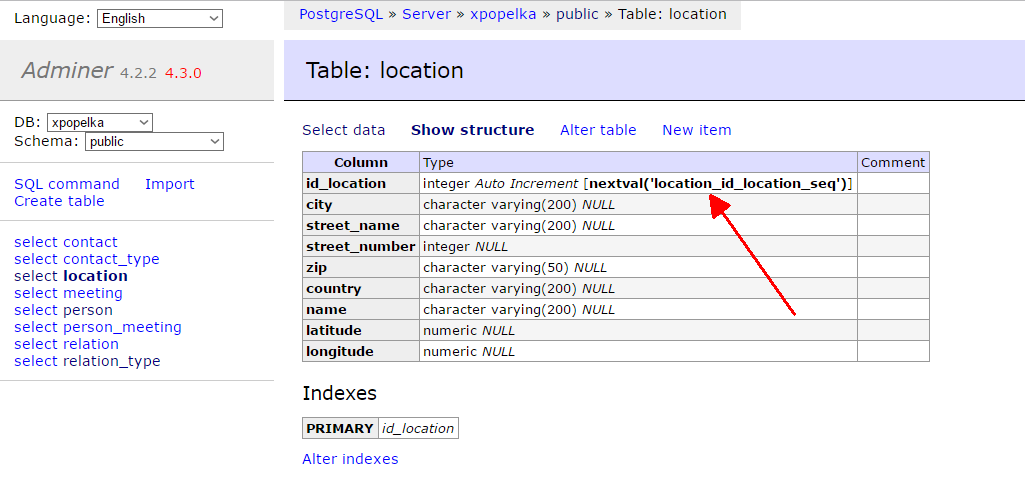
For this purpose the database has a mechanism which will return the last ID generated by an auto-increment
sequence requested by your INSERT in your database session. In Postgre SQL, each auto-increment sequence
has a name – you can find that name in the default value of the id column:
There is a CURRVAL(seq_name) SQL function which will return the last value of the auto-increment sequence in Postgre SQL and
this function takes as an argument the name of the sequence. Execute both commands at once in the Adminer:
INSERT INTO location (city) VALUES ('Bucharest');
SELECT CURRVAL('location_id_location_seq');Now you can search for the record with the returned ID – you should find a row with the city column set to Bucharest.
Notice that these two queries have to be executed in a single execution and therefore they have to be separated by a semicolon.
PHP Code
In PHP with the PDO library you can use the lastInsertId($sequenceName) method instead of executing separate SQL SELECT
command:
<?php
require 'include/start.php';
try {
$city = "Bucharest"; //replace with data from $_POST
$stmt1 = $db->prepare("INSERT INTO location (city) VALUES (:c)");
$stmt1->bindValue(":c", $city);
$stmt1->execute();
//obtain ID of new location
$addressID = $db->lastInsertId("location_id_location_seq");
$stmt2 = $db->prepare("INSERT INTO person
(..., id_location, ...)
VALUES
(..., :aid, ...)");
$stmt2->bindValue(":aid", $addressID);
$stmt2->execute();
} catch(PDOException $e) {
exit($e->getMessage());
}The lastInsertId($sequenceName) method picks the correct SQL command depending on the SQL server that you are using.
On PostgreSQL, this will be CURRVAL(seq_name). For example On MySQL this will be the LAST_INSERT_ID() function
which does not take any arguments and you do not have to pass $sequenceName into lastInsertId() function in that case.
In the above example, I have used two variables $stmt1 and $stmt2 for the queries. It is not necessary, because
I don’t need $stmt1 after $stmt2, so you can use only a single variable and overwrite it. In fact, it is
better to reuse the same variable if possible.
Error control and transactions
You already know that you have to enclose database communication in try-catch blocks. But what happens when the
first query (insert an address) is accepted and the second one (insert a person) is not? There can be more reasons than
you think for the second INSERT command to fail:
- the row you are inserting is not complete (some mandatory column has
NULLvalue). - the row you are inserting has a wrong data-type or range of one or more columns.
- the row you are inserting is in conflict with another row (uniqueness).
- the script is terminated from outside (a problem in another process, hardware failure, electric power loss…).
- the database server goes away – connection was terminated (i.e. problems with computer network, server crashed or is restarted).
Any of the above would result in a state in which you have the address in the database and not the person.
The user would try to insert the information again, but there will be an unused address record in the location table.
Even worse, it might be impossible to insert the address at all if it would violate record uniqueness.
To prevent this and other inconsistent states you want to enclose both queries into a transaction. This will make sure that both queries are either accepted by the database system and both rows are inserted into their tables or no row is inserted at all after the transaction ends.
<?php
require 'include/start.php';
try {
$db->beginTransaction(); //start transaction
$city = "Bucharest";
$stmt = $db->prepare("INSERT INTO location (city) VALUES (:c)");
$stmt->bindValue(":c", $city);
$stmt->execute();
$addressID = $db->lastInsertId("location_id_location_seq");
$stmt = $db->prepare("INSERT INTO person
(..., id_location, ...)
VALUES
(..., :aid, ...)");
$stmt->bindValue(":aid", $addressID);
$stmt->execute();
// if we got to this line, both rows are inserted, we can finish the transaction
$db->commit();
} catch(PDOException $e) {
$db->rollBack(); //undo all changes and finish the transaction
exit($e->getMessage());
}Either SQL query from my example may raise an exception and the program execution will jump into the catch block. When this
happens, the database will revert to the previous state thanks to rollback command. On the other hand, when everything goes
smooth, the changes are store permanently in the database using commit command.
The database system executes the SQL commands in transaction right away – it does not wait until the commit command.
The most important moment is when you begin the transaction, at that moment the database begins to record
your changes and you can revert to that state using rollback command. Your changes in database are available to you
during the transaction but no one else can see them.
Task – Play around with transactions
Take the first PHP script above and complete it so that it inserts data into the location and person tables. Or create your own with full working forms. Make sure to use the version without transactions. Then try to break
the second INSERT command (just make an error in the SQL command spelling, e.g. IxSERT instead of
INSERT). Observe the changes in the database. Then add the transaction commands (begin, commit, rollback)
and again observe what changes are made to the database. Do you notice the change of behavior?
Can you explain why it changed?
If you run the the script without the transaction commands, the first INSERT succeeds and the the location
will be inserted into the location table. It will remain there even if the other insert fails.
When you add the transaction commands, the behavior will change. If the first INSERT fails, and
raises an exception, the script will jump to catch statement and issue the rollback command.
This will roll back all SQL commands from the beginning of the transaction – in this case the
insert into the location table. Therefore the database will not contain the orphaned location record.
Summary
In this chapter I demonstrated how to insert multiple records which have some dependence among them. This requires using a last insert id value for the current database session. In the second part I described the importance of using transactions when inserting multiple rows.
New Concepts and Terms
- Generated sequence
- Database session
PDO::lastInsertId()- Transaction
Control question
- Why not use MAX() to obtain ID of last inserted row?
- How to determine the order of record insertion (e.g. insert address or person first)?